
پادشاهِ کُدنویسا شو!
برای حل این مسئله، راهحلهای مبتنی بر محاسبات درونحافظهای (In-Memory Computing) ظهور کردند. در این میان، In-Memory Data Grid (IMDG) یا «شبکه داده درونحافظهای» به عنوان یکی از پیشرفتهترین و کارآمدترین الگوهای معماری برای مدیریت دادههای توزیعشده و پردازشهای سنگین شناخته میشود.
در این مقاله تخصصی، به بررسی دقیق چیستی IMDG، معماری داخلی، تفاوتهای بنیادین آن با سیستمهای مشابه، الگوهای پیادهسازی و چالشهای مهندسی آن میپردازیم.
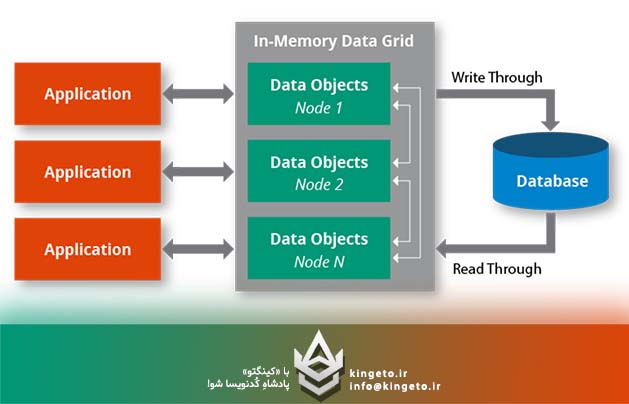
یک In-Memory Data Grid (IMDG) معماری پیچیدهای از سیستمهای توزیعشده است که حافظه رم (RAM) چندین سرور (Node) را به صورت یکپارچه و مجازی به یکدیگر متصل میکند تا یک استخر حافظه (Memory Pool) بزرگ، بسیار سریع و انعطافپذیر ایجاد کند. دادهها در این شبکه به صورت توزیعشده و در قالب کلید-مقدار (Key-Value) یا شیء (Object) ذخیره میشوند.
هدف اصلی IMDG، ارائه سرعت دسترسی در حد میکرواسکند، مقیاسپذیری افقی (Horizontal Scalability) غیرخطی، و فراهم کردن امکان پردازش موازی دادهها در محل ذخیرهسازی آنهاست.
در سیستمهای سنتی، فرمول مواجهه با داده به این صورت است: دادهها را از پایگاه داده بخوان، به سمت کد (Application Server) بیاور، پردازش کن و مجدداً ذخیره کن. این جابجایی داده در شبکه، گلوگاه اصلی سرعت است.
IMDG این فرمول را معکوس میکند: کد پردازشی (Logic) را به سمت محل استقرار دادهها در حافظه بفرست (Colocated Processing).
یک سیستم زمانی در دسته IMDG قرار میگیرد که ویژگیهای ساختاری زیر را به طور کامل پشتیبانی کند:
توزیعشدگی و شاردینگ داده (Data Sharding): دادهها به بخشهای کوچکی به نام پارتیشن (Partition) یا شارد تقسیم شده و به طور مساوی بین گرههای مختلف خوشه (Cluster) توزیع میشوند.
پایداری در برابر خطا (Fault Tolerance & High Availability): هر گره علاوه بر دادههای اصلی خود (Primary)، نسخههای پشتیبانی (Backup/Replica) از دادههای گرههای دیگر را نگهداری میکند. در صورت سقوط یک گره، گرههای دیگر فوراً جایگزین میشوند.
مقیاسپذیری خطی (Elastic Scalability): با افزودن گرههای جدید به خوشه، ظرفیت حافظه و قدرت پردازشی سیستم به طور همزمان و بدون نیاز به راهاندازی مجدد (Downtime)، افزایش مییابد.
پشتیبانی از تراکنشهای ACID: برخلاف بسیاری از سیستمهای NoSQL که مدل Eventual Consistency را دنبال میکنند، IMDGهای پیشرفته توانایی مدیریت تراکنشهای توزیعشده با پایبندی به اصول ACID (مانند پروتکل Two-Phase Commit) را دارا هستند.
یکی از اشتباهات رایج در مهندسی نرمافزار، یکسان فرض کردن IMDG با ابزارهای توزیعشده کَش (مانند Redis یا Memcached) یا پایگاههای داده درونحافظهای (In-Memory Databases) است. جدول زیر تمایز این سیستمها را به وضوح نشان میدهد:
| ویژگی | In-Memory Cache (مانند Redis) | In-Memory Database (مانند SAP HANA) | In-Memory Data Grid (مانند Hazelcast / Ignite) |
| هدف اصلی | کاهش بار پایگاه داده با ذخیره موقت دادههای پرمصرف | جایگزینی کامل پایگاه داده دیسکی با مدل حافظهمحور و SQL | پردازش توزیعشده و محاسبات موازی روی دادههای حجیم |
| مدل محاسباتی | عمدتاً تکرشتهای در هسته (Single-threaded) یا خوشهای ساده | پردازش متمرکز یا توزیعشده رابطهای (Relational) | پردازش هممکان (Colocated)، MapReduce و Compute Grid |
| تراکنشها | پشتیبانی محدود و ابتدایی از Transactions | پشتیبانی کامل از ACID متمرکز | پشتیبانی کامل از تراکنشهای توزیعشده (XA Transactions) |
| مقیاسپذیری | افقی (با ساختار Cluster محدود) | عمدتاً عمودی (Scale-up) | کاملاً افقی و پویا (Elastic Scale-out) |
| قابلیت کشف گره | نیازمند مدیریت دستی یا ابزارهای جانبی | ساختار ثابت کلاستر | خودکار (Auto-Discovery) بر پایه پروتکلهای شبکه |
معماری یک IMDG بر پایه مفاهیم پیشرفته سیستمهای توزیعشده بنا شده است. برای درک عمیق، باید به لایههای زیر نگاهی بیندازیم:
الف) توپولوژیهای ذخیرهسازی داده (Data Topologies)
IMDGها معمولاً از دو توپولوژی اصلی برای سازماندهی دادهها استفاده میکنند:
توپولوژی توزیعشده (Partitioned/Distributed Topology):
در این حالت، دادهها بر اساس هشِ کلید (Key Hash) بین گرهها تقسیم میشوند. هر گره فقط مالک بخشی از دادههاست. این الگو بالاترین میزان مقیاسپذیری را ارائه میدهد زیرا ظرفیت کل کلاستر برابر با مجموع حافظه تمامی گرههاست.
توپولوژی تکراری (Replicated Topology):
در این مدل، تمام دادهها روی تکتک گرهها کپی میشوند. سرعت خواندن (Read) در این روش فوقالعاده بالاست (چون عملیات کاملاً محلی است)، اما عملیات نوشتن (Write) به دلیل نیاز به همگامسازی همهجا، پرهزینه است و ظرفیت کلاستر محدود به حافظه ضعیفترین گره میشود.
ب) مکانیزم Near-Cache
برای بهینهسازی بیشتر، بسیاری از معماریهای IMDG از مفهومی به نام Near-Cache در سمت کلاینت (Application Server) استفاده میکنند. در این مکانیزم، دادههایی که توسط یک میکروسرویس به کرات خوانده میشوند، در حافظه محلی همان میکروسرویس نیز کَش میشوند تا حتی نیاز به سفر درونشبکهای به سمت گرههای کلاستر IMDG نیز از بین برود. چالش اصلی در اینجا، مدیریت ابطال کَش (Cache Invalidation) به محض تغییر دادهها در کلاستر اصلی است که توسط سیگنالهای توزیعشده IMDG مدیریت میشود.
ج) پایداری داده (Data Persistence)
با وجود اینکه ماهیت IMDG بر پایه RAM است، اما برای جلوگیری از دست رفتن دادهها در اثر قطعی کامل برق یا کرش کلاستر، از استراتژیهای پایداری استفاده میشود:
Write-Through: داده همزمان در IMDG و پایگاه داده دیسکی جانبی نوشته میشود. امنیت بالا، سرعت نوشتن کمتر.
Write-Behind (Asynchronous): داده ابتدا با سرعت بالا در IMDG نوشته شده و کلاینت آزاد میشود؛ سپس به صورت ناهمگام و در دستههای مشخص (Batching) به پایگاه داده زیرین منتقل میشود.
بزرگترین متمایزکننده IMDG، بخش Compute Grid آن است. در معماریهای سنتی، اگر بخواهید حقوق تمام کارکنان یک سازمان را ۱۰ درصد افزایش دهید، باید میلیونها رکورد را از دیسک یا کَش بخوانید، در لایه اپلیکیشن پردازش کنید و دوباره به منبع بفرستید.
در IMDG، شما کدی (مثلاً یک کالبک، لاندا یا تصدیقکننده) را تحت عنوان Entry Processor مینویسید. این کد به کلاستر ارسال میشود. IMDG هوشمند است؛ کد را مستقیماً به گرههایی میفرستد که پارتیشنهای مربوط به دادههای حقوق کارکنان در آنها قرار دارد. پردازش در همانجا، به صورت کاملاً موازی و بدون هیچگونه جابجایی داده در شبکه (Network Serialization) انجام شده و فقط نتیجه نهایی (Success/Failure) برگردانده میشود.
قاعده طلایی معماری:
هزینه پهنای باند شبکه و پردازش سریال داده بسیار بیشتر از هزینه انتقال یک قطعه کد چند کیلوبایتی به محل استقرار داده است.
در معماریهای سازمانی (Enterprise Architectures)، استفاده از IMDG میتواند الگوهای زیر را بهینهسازی کند:
۱. بهینهسازی الگوی CQRS (Command Query Responsibility Segregation)
۲. الگوی الگوهای معماری رویدادمحور (Event-Driven Architecture)
استفاده از این فناوری شاه کلید نیست که تمام مشکلات را حل کند؛ پیادهسازی آن چالشهای عمیقی به همراه دارد:
الف) مسئله Split-Brain (مغز دونیم شده)
در صورت بروز نقص در شبکه ارتباطی بین گرهها (Network Partition)، ممکن است کلاستر به دو بخش مجزا تقسیم شود و هر بخش گمان کند بخش دیگر از بین رفته است. در این حالت، هر دو بخش اقدام به تعیین گره لیدر (Leader) کرده و شروع به پذیرش دسترسیهای نوشتن میکنند. این امر منجر به تناقض شدید داده (Data Divergence) میشود.
راهکار: IMDGها از الگوریتمهای اجماع (Consensus Algorithms) مانند Raft یا سیستمهای حد نصاب (Quorum) استفاده میکنند تا در صورت بروز Split-Brain، بخشی که حد نصاب اعضا (نصف + ۱) را ندارد، فوراً متوقف کند.
ب) مدیریت حافظه و اورهد Serialization
از آنجا که اکثر IMDGهای معروف (مانند Hazelcast و Apache Ignite) بر پایه زبان جاوا (JVM) توسعه یافتهاند، مدیریت حافظه و فرار از توقفهای طولانیمدت ناشی از جمعآوری زباله حافظه (Garbage Collection Pauses) یک چالش بزرگ است. برای حل این مشکل، این ابزارها از حافظههای خارج از هیت JVM (Off-Heap Memory) استفاده میکنند تا کنترل مدیریت حافظه را مستقیماً به سیستمعامل بسپارند. همچنین، اشیاء قبل از ارسال به شبکه باید سریالایز (Serialized) شوند که طراحی کاستوم سریالایزرها برای کارایی بالا الزامی است.
ج) قضیه CAP (CAP Theorem)
بر اساس تئوری CAP، در زمان بروز پارتشین شبکه (P)، یک سیستم توزیعشده باید بین یکپارچگی (Consistency) و در دسترس بودن (Availability) یکی را انتخاب کند. IMDGها معمولاً به گونهای پیکربندی میشوند که مدل CP (تمرکز بر صحت و یکپارچگی دادهها) را پاس بدارند، چرا که برای تراکنشهای مالی و حساس استفاده میشوند. با این حال، تنظیم آنها روی مدل AP نیز در موارد خاص امکانپذیر است.
اگر قصد انتخاب یک پایگاه تکنولوژی برای پیادهسازی این معماری را دارید، گزینههای زیر استاندارد بازار هستند:
[ابزارهای شاخص IMDG]
├── Apache Ignite (دارای لایه قوی پایداری دیسک + پشتیبانی کامل از SQL-92)
├── Hazelcast (بسیار سبک، توسعه آسان، یکپارچگی فوقالعاده با کلاستر کابرنتیز)
├── Oracle Coherence (یکی از قدیمیترینها، مناسب برای انترپرایزهای بزرگ با بودجه بالا)
└── VMware Tanzu GemFire (قدرتمند در مقیاسهای بسیار عظیم و تراکنشهای مالی حساس)
شبکه داده درونحافظهای یا IMDG، فراتر از یک ابزار ساده برای کَش کردن دادههاست. این فناوری یک الگوی معماری توزیعشده است که با تلفیق مفاهیم ذخیرهسازی درونحافظهای و محاسبات هممکان (Colocated Innovation)، سقف جدیدی از کارایی و مقیاسپذیری را برای سیستمهای نرمافزاری مدرن فراهم کرده است.
انتخاب یک IMDG زمانی منطقی است که سیستم شما با حجم عظیمی از دادههای در حال تغییر مواجه است، نیاز به پردازشهای سنگین و آنالیزهای بلادرنگ دارد و پایگاههای داده ریلیشنال یا حتی کَشهای ساده کلید-مقدار، به دلیل هزینههای بالای I/O و جابجایی شبکه، توان پاسخگویی به توافقنامه سطح خدمات (SLA) شما را ندارند. پیادهسازی موفق آن نیازمند درک عمیق از تئوری سیستمهای توزیعشده، مدیریت حافظه و الگوهای همگامسازی داده است.















0 نظر
هنوز نظری برای این مقاله ثبت نشده است.