
پادشاهِ کُدنویسا شو!
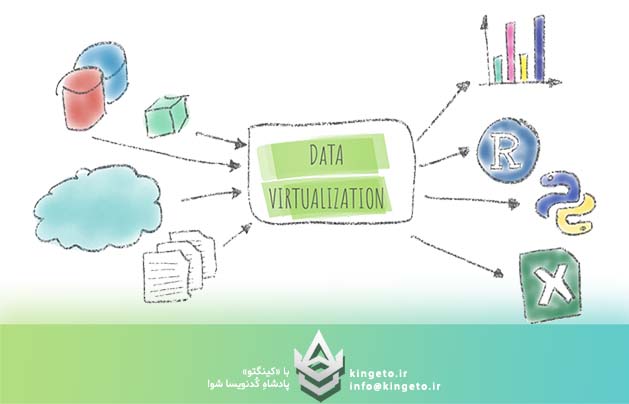
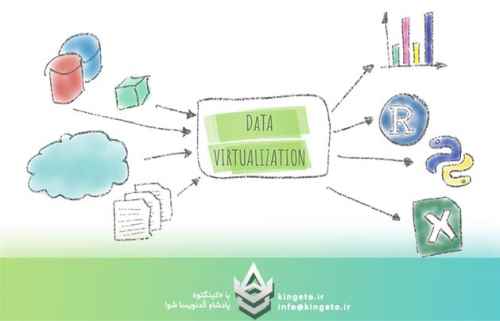
نتیجه این توسعه ناهمگون، ایجاد جزایر اطلاعاتی (Data Silos) است. به طور سنتی، راهکار حل این مشکل استفاده از فرآیندهای سنگین ETL (Extract, Transform, Load) و انتقال دادهها به یک انبار داده مرکزی (Data Warehouse) یا دریاچه داده (Data Lake) بوده است. اما معماریهای مبتنی بر کپیبرداری و جابجایی فیزیکی دادهها با چالشهای ساختاری جدی روبرو هستند:
تاخیر زمانی بالادر دسترسی به دادهها (Latency): فرآیندهای ETL معمولاً به صورت دورهای (مثلاً شبانه) اجرا میشوند؛ بنابراین دادههای تحلیلشده هرگز کاملاً بهروز (Real-time) نیستند.
هزینههای سرسامآور ذخیرهسازی و زیرساخت: کپی کردن ترابایتها داده از محیطهای مختلف به یک نقطه مرکزی، پهنای باند شبکه و فضای ذخیرهسازی مضاعفی را طلب میکند.
پیچیدگی در نگهداری و حاکمیت داده (Data Governance): تغییر در ساختار (Schema) یکی از دیتابیسهای مبدا، کل خط لوله (Pipeline) ETL را با شکست مواجه میکند. همچنین اعمال استانداردهای امنیتی یکپارچه روی دادههای تکثیرشده بسیار دشوار است.
در پاسخ به این چالشها، مفهوم مجازیسازی دادهها (Data Virtualization) به عنوان یک الگوی معماری مدرن و انقلابی ظهور کرده است. این مقاله با دیدگاهی فنی و ساختاریافته، به بررسی عمیق این فناوری، لایههای معماری آن و نحوه پیادهسازی آن برای دسترسی یکپارچه میپردازد.
مجازیسازی دادهها یک رویکرد مدیریت داده است که به برنامهها و کاربران اجازه میدهد بدون نیاز به دانستن جزئیات فنی درباره مکان فیزیکی، فرمت ذخیرهسازی یا نحوه ساختاریافتگی دادهها، به آنها دسترسی داشته باشند و آنها را دستکاری کنند.
اصل اساسی مجازیسازی دادهها: دسترسی به دادهها در زمان واقعی (Real-time) بدون جابجایی یا کپی کردن فیزیکی آنها از منبع اصلی.
به عبارت سادهتر، این فناوری یک لایه انتزاعی منطقی (Logical Abstraction Layer) روی تمام منابع دادهای سازمان ایجاد میکند. از دید مصرفکننده (یک داشبورد مدیریتی، یک کامپوننت نرمافزاری یا یک مدل هوش مصنوعی)، تمام سازمان مانند یک دیتابیس واحد و یکپارچه به نظر میرسد، در حالی که در پشت صحنه، دادهها در دهها سیستم ناهمگون قرار دارند.
تفاوت بنیادین: Data Virtualization در برابر Data Federation و ETL
برای درک بهتر، مقایسه این فناوریها در جدول زیر آورده شده است:
| ویژگی | فرآیند سنتی ETL | فدراسیون داده (Data Federation) | مجازیسازی دادهها (Data Virtualization) |
| جابجایی فیزیکی داده | بله (دادهها کپی و منتقل میشوند) | خیر (دادهها در مبدا میمانند) | خیر (دادهها در مبدا میمانند) |
| تأخیر (Latency) | بالا (مبتنی بر دستههای زمانبندی شده) | کم (در لحظه) | بسیار کم (بهینهسازی شده با مکانیزمهای کش) |
| مفهوم لایه انتزاع | ندارد (داده فیزیکی است) | ضعیف (صرفاً اتصال چند دیتابیس مشابه) | بسیار قوی (پوشش انواع ساختارهای SQL، NoSQL، API) |
| حاکمیت و امنیت داده | توزیع شده در مخازن مختلف | وابسته به سیستمهای مبدا | متمرکز در لایه مجازیسازی |
یک خط لوله استاندارد مجازیسازی دادهها از چهار لایه منطقی و اصلی تشکیل شده است که وظیفه تبدیل دادههای خام و پراکنده به اطلاعات تجاری ارزشمند را بر عهده دارند:
+-------------------------------------------------------------+
| لایه مصرف (BI, APIs, Apps) |
+-------------------------------------------------------------+
|
+-------------------------------------------------------------+
| لایه کسبوکار و انتزاع (Business & Semantic) |
+-------------------------------------------------------------+
|
+-------------------------------------------------------------+
| لایه یکپارچهسازی و بهینهسازی کوئری (Execution & Query) |
+-------------------------------------------------------------+
|
+-------------------------------------------------------------+
| لایه اتصال فیزیکی (Physical Connectors) |
+-------------------------------------------------------------+
الف) لایه اتصال (Connectivity Layer)
این لایه وظیفه برقراری ارتباط با انواع منابع داده فیزیکی را بر عهده دارد. موتور مجازیسازی به کمک کانکتورهای اختصاصی (مانند JDBC، ODBC، امپراتورهای NoSQL و کلاینتهای REST/GraphQL) پروتکلهای محلی هر منبع داده را شبیهسازی میکند.
ب) لایه یکپارچهسازی و بهینهسازی کوئری (Integration & Optimization Layer)
قلب تپنده سیستم اینجاست. زمانی که کاربر یک کوئری ترکیبی ارسال میکند، این لایه وظیفه دارد آن را به تکههای کوچکتر شکسته، هر تکه را متناسب با زبان منبع مقصد (مثلاً تبدیل به یک دستور Aggregation در MongoDB یا یک لایهی Select در SQL Server) بازنویسی کند. این فرآیند تحت عنوان Cost-Based Optimization (CBO) شناخته میشود.
ج) لایه کسبوکار و انتزاع (Abstraction & Semantic Layer)
در این لایه، ساختارهای فنی دیتابیسها به مفاهیم تجاری تبدیل میشوند. به عنوان مثال، جدول tbl_usr_2026 در یک دیتابیس قدیمی و سند customer_profile در دیتابیس تکاملیافته جدید، ترکیب شده و به عنوان یک موجودیت واحد و تمیز به نام Customer تعریف میشوند. تغییرات در دیتابیسهای فیزیکی در این لایه خنثی شده و آسیبی به کدهای فرانتاند نمیزند.
د) لایه مصرف (Consumer Layer)
این لایه، درگاههای خروجی استاندارد را برای سیستمهای بالادستی فراهم میکند. کاربران و برنامهها میتوانند از طریق اینترفیسهای استانداردی همچون استاندارد ANSI SQL، وبسرویسهای RESTful، پروتکل OData یا بسترهای مانیتورینگ نظیر PowerBI به این لایه متصل شوند.
بزرگترین شبههای که مهندسان نرمافزار در مواجهه با مجازیسازی دادهها مطرح میکنند این است: «چگونه کارایی (Performance) افت نمیکند وقتی کپی فیزیکی وجود ندارد و دادهها باید در لحظه از چندین منبع مختلف واکشی و ترکیب شوند؟»
این یک دغدغه کاملاً معتبر است. اگر یک موتور مجازیسازی ضعیف طراحی شده باشد، یک عملیات JOIN بین یک جدول ۱۰ میلیون رکوردی در Oracle و یک فایل ۳ گیگابایتی در Amazon S3 میتواند کل پهنای باند شبکه سازمان را فلج کند. سیستمهای مدرن معماری داده برای حل این مشکل از سه تکنیک کلیدی استفاده میکنند:
۱. پردازش موازی انبوه (Massively Parallel Processing - MPP)
موتورهای مدرن مجازیسازی داده از معماریهای توزیعشده (Cluster-based) استفاده میکنند. اجرای کوئریها بین چندین گره (Node) کامپیوتری تقسیم میشود تا پردازش نهایی، فیلترینگ و مرتبسازی دادههای دریافتی به صورت موازی انجام گیرد.
۲. تکنیک بهینهسازی Pushdown Optimization
این کانسپت حیاتی به این معناست که موتور مجازیسازی تا جای ممکن عملیات پردازش، فیلترینگ (WHERE) و مجمعسازی (GROUP BY) را به خود دیتابیسهای منبع واگذار میکند.
سناریوی بد: دریافت تمام ۱۰ میلیون رکورد از شبکه و فیلتر کردن آنها در لایه مجازیسازی.
سناریوی Pushdown: ارسال دستور فیلترینگ به خود دیتابیس اصلی، دریافت صرفاً ۱۰۰ رکورد نهایی و بهینهشده از طریق شبکه.
۳. حافظه پنهان هوشمند و پویا (Smart Caching & Materialization)
برای دادههایی که نرخ تغییرات کمی دارند اما به وفور فراخوانی میشوند (مانند کدهای پستی یا لیست استانها)، لایه مجازیسازی یک کپی موقت و زماندار (TTL) را در یک حافظه موقت بسیار سریع (مانند دیتابیسهای درونحافظهای یا NVMe Storage) ذخیره میکند. سیستم به صورت خودکار کوئریهای تکراری را شناسایی کرده و بدون مراجعه به منابع اصلی، از لایه کش پاسخ میدهد.
پراکندگی دادهها معمولاً کابوس تیمهای امنیت شبکه است؛ چرا که اعمال پروتکلهای امنیتی روی دهها پلتفرم مختلف به صورت مجزا، احتمال خطای انسانی را به شدت افزایش میدهد. مجازیسازی دادهها با ایجاد یک نقطه گلوگاهی واحد (Single Point of Access)، این چالش را به یک فرصت تبدیل میکند.
+--------------------------------+
| داشبوردها، اپلیکیشنها، کاربران |
+--------------------------------+
|
v [دسترسی از طریق یک پروتکل واحد]
+--------------------------------------------------------------------------+
| لایه امنیت مرکزی مجازیسازی |
| - احراز هویت متمرکز (OAuth2 / Active Directory) |
| - کنترل دسترسی بر اساس نقش (RBAC) و ویژگی (ABAC) |
| - ماسکگذاری پویا روی دادهها (Dynamic Data Masking) |
+--------------------------------------------------------------------------+
| | |
v v v
+------------------+ +------------------+ +------------------+
| سیستم مالی | | سامانه فروش | | دیتابیس کاربران |
+------------------+ +------------------+ +------------------+
کنترل دسترسی متمرکز (RBAC & ABAC): شما میتوانید به جای تعریف سطوح دسترسی در تکتک دیتابیسها، قوانین دسترسی را در لایه مجازیسازی پیاده کنید. به عنوان مثال: «کاربران دپارتمان بازاریابی حق دیدن ستون شماره تماس را ندارند».
ماسکگذاری پویا بر روی دادهها (Dynamic Data Masking): دادههای حساس مانند شماره کارتهای بانکی یا کدهای ملی در حین عبور از لایه مجازیسازی و قبل از تحویل به کاربر نهایی، به صورت خودکار متناسب با سطح دسترسی کاربر ماسکگذاری میشوند (مثلاً ****5678).
حسابرسی و لاگگیری یکپارچه (Unified Auditing): ردیابی این که چه کسی، در چه زمانی، به چه دادهای و از کدام منبع فیزیکی دسترسی داشته است، در یک هاب متمرکز ثبت میشود که برای رعایت استانداردهایی نظیر GDPR عالی است.
برای یک تیم مهندسی نرمافزار پیشرو، استفاده از مجازیسازی دادهها شتابدهنده قدرتمندی برای الگوهای معماری نوین است:
تسریع توسعه ریزخدمات (Microservices)
یکی از چالشهای بزرگ در معماری میکروپروایدرها، نیازمندی به دادههای مشترک است. طبق اصول طراحی، هر میکروسرویس باید دیتابیس اختصاصی خود را داشته باشد. اما زمانهایی پیش میآید که یک سرویس گزارشگیری کلان نیاز به ترکیب دادههای چندین میکروسرویس دارد. به جای ایجاد وابستگیهای شدید API بین سرویسها (API Chaining) که سیستم را شکننده میکند، لایه مجازیسازی داده میتواند یک نمای خواندنی (Read-Only View) یکپارچه از دیتابیسهای تمام میکروسرویسها را بدون شکستن مرزهای دامنه (Bounded Contexts) آنها ارائه دهد.
پیادهسازی الگوی CQRS
در الگوهای CQRS (Command Query Responsibility Segregation)، لایه مجازیسازی دادهها میتواند به عنوان یک مکانیزم فوقالعاده برای بخش Query (خواندنی) عمل کند. این لایه قادر است درخواستهای پیچیده خواندن را مدیریت کرده و با ترکیب دادههای تراکنشی و دادههای آرشیو شده، بار سنگین پردازشی را از روی بخش Command بردارد.
رویکردهای سنتی مدیریت و یکپارچهسازی دادهها که بر پایه جابجایی فیزیکی (ETL) استوار هستند، دیگر پاسخگوی حجم، سرعت و تنوع دادههای مدرن در سال ۲۰۲۶ نیستند. مجازیسازی دادهها (Data Virtualization) با ارائه یک لایه انتزاعی هوشمند، منطقی و بلادرنگ، پارادایم جدیدی را معرفی میکند که هزینههای زیرساختی را کاهش، حاکمیت داده را صلب و سرعت توسعه نرمافزار را به شدت افزایش میدهد.
برای سازمانهایی که به دنبال چابکی، کاهش تاخیر در تصمیمگیریهای مبتنی بر داده و رهایی از پیچیدگیهای نگهداری خطوط لوله طولانی انتقال داده هستند، پذیرش و پیادهسازی معماری مجازیسازی دادهها نه یک انتخاب لوکس، بلکه یک ضرورت استراتژیک در مهندسی مدرن اطلاعات است.













0 نظر
هنوز نظری برای این مقاله ثبت نشده است.