
پادشاهِ کُدنویسا شو!
در سیستمهای قدیمی، مدیریت تراکنشها ساده بود؛ یک بانک اطلاعاتی رابطهای (RDBMS) با مکانیزمهای بومی خود، تراکنشهای ACID را تضمین میکرد. اما در دنیای دیتابیسهای توزیعشده و میکروسرویسها که در آن هر سرویس بانک اطلاعاتی اختصاصی خود را دارد (Database-per-Service)، دیگر خبری از دستورات ساده BEGIN TRANSACTION و COMMIT نیست.
برای حل این چالش، الگوی Saga به عنوان یکی از پختهترین و استانداردترین راهکارهای معماری نرمافزار مطرح شده است. در این مقاله تخصصی، به کالبدشکافی عمیق مدیریت تراکنشهای توزیعشده، چرایی شکست الگوهای سنتی و نحوه پیادهسازی و مدیریت چالشهای Saga Pattern میپردازیم.
پیش از ابداع ساگا، مهندسان سیستم تلاش کردند تا با استفاده از پروتکل Two-Phase Commit (2PC) تراکنشهای توزیعشده را مدیریت کنند. در این پروتکل، یک هماهنگکننده مرکزی (Coordinator) در دو مرحله (Prepare و Commit) از تمام گرهها تاییدیه میگیرد.
با وجود اینکه 2PC یکپارچگی قوی (Strong Consistency) را تضمین میکند، اما در سیستمهای توزیعشده مدرن با چالشهای زیر روبروست:
مسئله انسداد (Blocking): اگر هماهنگکننده یا یکی از گرهها در مرحله تایید دچار وقفه (Timeout) یا خرابی شود، تمام قفلهای دیتابیس (Database Locks) باز میمانند و کل سیستم قفل میشود.
تئوری CAP و کاهش کارایی: بر اساس تئوری CAP، در زمان بروز خطای شبکه، نمیتوان همزمان دسترسیپذیری بالا (Availability) و یکپارچگی قوی (Consistency) داشت. پروتکل 2PC دسترسیپذیری را فدای یکپارچگی میکند که این امر منجر به افزایش شدید زمان پاسخدهی (Latency) میشود.
نتیجه معماری: در سیستمهای توزیعشده با تراکنشهای پرحجم، ما باید به سمت یکپارچگی نهایی (Eventual Consistency) حرکت کنیم و این دقیقاً نقطهای است که Saga Pattern وارد بازی میشود.
الگوی ساگا اولین بار در سال ۱۹۸۷ در مقالهای دانشگاهی توسط هکتور گارسیا مولینا و کنت سالم مطرح شد. ایده اصلی ساگا بسیار ساده اما قدرتمند است:
به جای اجرای یک تراکنش بزرگ و فراگیر که کل سیستم را قفل میکند، تراکنش توزیعشده را به مجموعهای از تراکنشهای محلی (Local Transactions) تقسیم کن که پشت سر هم اجرا میشوند.
در این الگو، هر سرویس تراکنش محلی خود را در دیتابیس اختصاصیاش اجرا کرده و پس از اتمام، یک رویداد (Event) یا پیام (Message) منتشر میکند تا سرویس بعدی تحریک شود.
اگر یک تراکنش توزیعشده شامل $n$ مرحله باشد، میتوان آن را به صورت زیر نمایش داد:
$$Saga = \{T_1, T_2, T_3, ..., T_n\}$$
هر $T_i$ یک تراکنش محلی مستقل است که فوراً در دیتابیس مربوطه Commit میشود.
مفهوم حیاتی: تراکنشهای جبرانی (Compensating Transactions)
از آنجا که هر مرحله فوراً Commit میشود، اگر سیستم در مرحله $T_3$ با خطا مواجه شود، امکان Rollback سنتی وجود ندارد (چون دادههای $T_1$ و $T_2$ قبلاً روی دیتابیس نشسته و نهایی شدهاند).
برای حل این مشکل، برای هر تراکنش محلی ($T_i$)، باید یک تراکنش جبرانی ($C_i$) تعریف شود. وظیفه تراکنش جبرانی، خنثی کردن اثرات تراکنش اصلی و بازگرداندن سیستم به حالت منطقی قبلی است (یک نوع رولبک در لایه اپلیکیشن).
اگر تراکنش در مرحله $T_3$ شکست بخورد، ساگا مسیر معکوس را طی میکند:
$$Failure\ Path = \{T_1, T_2, T_3 (Fail), C_2, C_1\}$$
الگوی ساگا را میتوان به دو روش کاملاً متفاوت از نظر تفکر معماری پیادهسازی کرد: کوروگرافی (Choreography) و ارکستراسیون (Orchestration).
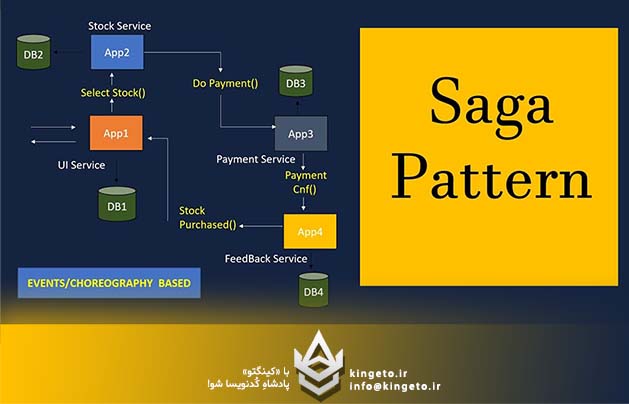
الف) روش کوروگرافی (Choreography-based Saga)
در این مدل، هیچ هماهنگکننده یا لیدر مرکزی وجود ندارد. سرویسها کاملاً مستقل هستند و بر اساس رویدادهایی که در سیستم منتشر میشود (معمولاً از طریق یک Message Broker مانند Kafka یا RabbitMQ) متوجه وظیفه خود شده و آن را اجرا میکنند.
نحوه کارکرد: سرویس الف کار خود را انجام میدهد و رویداد OrderCreated را منتشر میکند. سرویس ب به این رویداد گوش میدهد، پول را کسر میکند و رویداد PaymentApproved را صادر میکند. سرویس ج انبار را بهروز میکند.
مزایا:
ساختار ساده و جفتشدگی بسیار پایین (Loose Coupling).
عدم وجود نقطه شکست واحد (No Single Point of Failure).
معایب:
پیچیدگی درک جریان سیستم با افزایش تعداد سرویسها (خوانایی پایین).
ریسک ایجاد وابستگیهای چرخشی (Cyclic Dependencies).
دشواری شدید در دیباگ و تست کل فرآیند.
ب) روش ارکستراسیون (Orchestration-based Saga)
در این مدل، یک سرویس یا کامپوننت اختصاصی به نام ارکستراتور (Orchestrator) وظیفه مدیریت و رهبری کل تراکنش را بر عهده دارد. ارکستراتور مشخص میکند که کدام سرویس در چه زمانی باید چه کاری را انجام دهد و در صورت بروز خطا، دستور اجرای تراکنشهای جبرانی را صادر میکند.
نحوه کارکرد: ارکستراتور پیام میدهد: "سرویس پرداخت، پول را کسر کن". سرویس پاسخ مثبت میدهد. ارکستراتور به سرویس انبار پیام میدهد: "موجودی را کم کن". اگر انبار خطا داد، ارکستراتور به سرویس پرداخت پیام میدهد: "تراکنش جبرانی را اجرا کن و پول را برگشت بزن".
مزایا:
جریان تراکنش در یک جا متمرکز و مستند است (فوقالعاده برای نگهداری سیستم).
سرویسهای دیگر نیازی به دانستن رویدادهای یکدیگر ندارند و کاملاً ایزوله میمانند.
مدیریت تراکنشهای جبرانی بسیار سادهتر و دقیقتر است.
معایب:
خطر تبدیل شدن ارکستراتور به یک کلاستر پیچیده و نقطه شکست واحد (اگر به درستی Scale نشود).
اضافه شدن یک لایه اورهد و منطق اضافه به معماری شبکه.
| معیار ارزیابی | Choreography (کوروگرافی) | Orchestration (ارکستراسیون) |
| کنترل مرکزی | ندارد (غیرمتمرکز) | دارد (متمرکز) |
| میزان جفتشدگی (Coupling) | بسیار پایین | متوسط (وابستگی به ارکستراتور) |
| پیچیدگی پیادهسازی | در ابتدا آسان، در مقیاس بالا کابوس | در ابتدا نیازمند طراحی دقیق، در مقیاس بالا پایدار |
| مدیریت خطا (Rollback) | دشوار و نیازمند پیگیری زنجیرهای رویدادها | بسیار آسان و سیستماتیک |
| مناسب برای... | تراکنشهای کوچک با ۲ الی ۴ مرحله | تراکنشهای پیچیده سازمانی با مراحل متعدد |
اگر به اصول ACID نگاه کنیم، حرف I نماینده Isolation (ایزولاسیون) است؛ یعنی تراکنشهای همزمان نباید دادههای میانی یکدیگر را ببینند. اما در الگوی ساگا، از آنجا که هر سرویس فوراً تراکنش محلی خود را Commit میکند، اصل ایزولاسیون کاملاً نقض میشود. به این معماری اصطلاحاً ACD میگویند (بدون Isolation).
این نقص ساختاری منجر به بروز ۳ ناهنجاری (Anomaly) عمده در دادهها میشود:
Lost Updates (بهروزرسانیهای گمشده): ساگا ۱ دادهای را تغییر میدهد، ساگا ۲ بدون اطلاع، روی همان داده مینویسد، سپس ساگا ۱ شکست خورده و تراکنش جبرانی را اعمال میکند؛ در نتیجه تغییرات ساگا ۲ نیز از بین میرود!
Dirty Reads (خواندن کثیف): یک کاربر یا سرویس دیگر، دادههای میانی و موقتی که توسط یک ساگا تغییر کرده اما هنوز کل زنجیره آن تایید نشده است را میخواند.
Fuzzy/Non-repeatable Reads: یک سرویس در ابتدای ساگا دادهای را میخواند و در انتهای ساگا همان داده را مجدداً بررسی میکند، اما سرویس دیگری در این میان داده را تغییر داده است.
راهکارهای مهندسی برای جبران نبود ایزولاسیون (Countermeasures)
برای حل این آنومالیها، طراحان معماری از تکنیکهای زیر استفاده میکنند:
قفل معنایی (Semantic Lock): در ابتدای ساگا، فیلدی به نام Status در رکورد ایجاد میشود و مقدار آن به Pending یا Lock تغییر میکند. سرویسهای دیگر با دیدن این وضعیت، متوجه میشوند که این داده در حال پردازش در یک ساگای دیگر است و نباید آن را تغییر دهند.
بهروزرسانیهای جابجاییپذیر (Commutative Updates): طراحی تراکنشها به گونهای که ترتیب اجرای آنها اهمیتی نداشته باشد (مانند عملیات ریاضی جمع و تفریق روی کیف پول).
دیدگاه بدبینانه (Pessimistic View): بازطراحی مراحل ساگا به شکلی که ریسکیترین و حساسترین کارها (مانند کسر واقعی پول) در آخرین مرحله ممکن انجام شوند تا احتمال نیاز به تراکنش جبرانی به حداقل برسد.
برای درک کامل، یک سناریوی خرید را در نظر بگیرید که شامل چهار سرویس است: Order (سفارش)، Payment (پرداخت)، Stock (انبار) و Delivery (ارسال).
سناریوی موفقیت (Success Path) در مدل ارکستراسیون
کلاینت درخواست ثبت سفارش میدهد.
سرویس سفارش رکورد را با وضعیت PENDING_PAYMENT ایجاد میکند و ساگا شروع میشود.
ارکستراتور به سرویس پرداخت دستور کسر وجه میدهد $\rightarrow$ وضعیت: موفق.
ارکستراتور به سرویس انبار دستور تخصیص کالا میدهد $\rightarrow$ وضعیت: موفق.
ارکستراتور به سرویس سفارش دستور میدهد وضعیت را به CONFIRMED تغییر دهد. ساگا خاتمه مییابد.
فرض کنید در مرحله ۴، انبار متوجه میشود که کالا آسیب دیده و موجودی واقعی صفر است.
[شروع] ──> ۱. ثبت سفارش (OK) ──> ۲. کسر وجه (OK) ──> ۳. بررسی انبار (شکست!)
│
[پایان] <── وضعیت سفارش: لغو شد <── ۵. برگشت وجه (C1) <──────────┘
سرویس انبار خطای OUT_OF_STOCK را به ارکستراتور بازمیگرداند.
ارکستراتور متوجه شکست زنجیره میشود.
ارکستراتور تراکنش جبرانی $C_1$ را به سرویس پرداخت میفرستد: Refund Money. پول به حساب مشتری بازمیگردد.
ارکستراتور تراکنش جبرانی بعدی را به سرویس سفارش میفرستد: Change Status to CANCELLED.
دادهها به حالت امن اولیه بازمیگردند و سیستم دچار تناقض نمیشود.
مدیریت تراکنش در سیستمهای توزیعشده موازنه زیبایی بین پیچیدگی و کارایی است. الگوی ساگا (Saga Pattern) با پذیرش واقعیتِ "یکپارچگی نهایی" به سیستمهای بزرگ اجازه میدهد بدون قفل کردن منابع شبکه و پایگاه داده، تراکنشهای طولانیمدت و پیچیده را با امنیت بالا مدیریت کنند.
انتخاب بین کوروگرافی و ارکستراسیون بستگی به اندازه پروژه شما دارد؛ برای سیستمهای کوچک، کوروگرافی به دلیل عدم نیاز به زیرساخت اضافی جذاب است، اما برای سیستمهای Enterprise و بزرگ، ارکستراسیون با وجود هزینه اولیه بالاتر، به دلیل قابلیت مانیتورینگ و خطایابی متمرکز، گزینه بسیار امنتری به شمار میرود. پیادهسازی موفق ساگا نیازمند بازنگری در مدل ذهنی تراکنشها و تسلط بر مدیریت چالشهای ناشی از عدم ایزولاسیون دادههاست.















0 نظر
هنوز نظری برای این مقاله ثبت نشده است.